
Generation を引用付きで書く — Anthropic Citations API と cross-encoder reranker
2026-05-24 改訂: 本シリーズは Ollama + Qwen3 で完全ローカル再現できる構成に作り直しました。reranker (cross-encoder) と検索スコアは
qwen3-embedding:0.6b+ms-marco-MiniLM-L-6-v2で 実測した値 です。ただし本記事後半の Anthropic Citations API は Anthropic 固有機能 なので、その節だけは Anthropic キーが必要です (構造は--mockでも確認できます)。題材は架空企業「ナギサ・パートナーズ」の社内 wiki です。
Part 1 で「動くけど使えない」失敗を 3 グループに整理し、Part 2 で hybrid+filter により旧版 (archived) を top-5 から追い出しました。けれど Part 2 末尾で天井を 2 つ残したはずです。意味的に近い trap (LT 大会の評価基準) が hybrid でむしろ 2 位に上がる こと (グループ A-2)、そして 「どの doc が根拠か」を読者が検証できない こと (グループ C-1)。本記事 (Part 3) では前者を cross-encoder reranker で top-20 から top-3 まで絞り、後者を Anthropic Citations API で doc_id 付きの grounding に置き換えます。
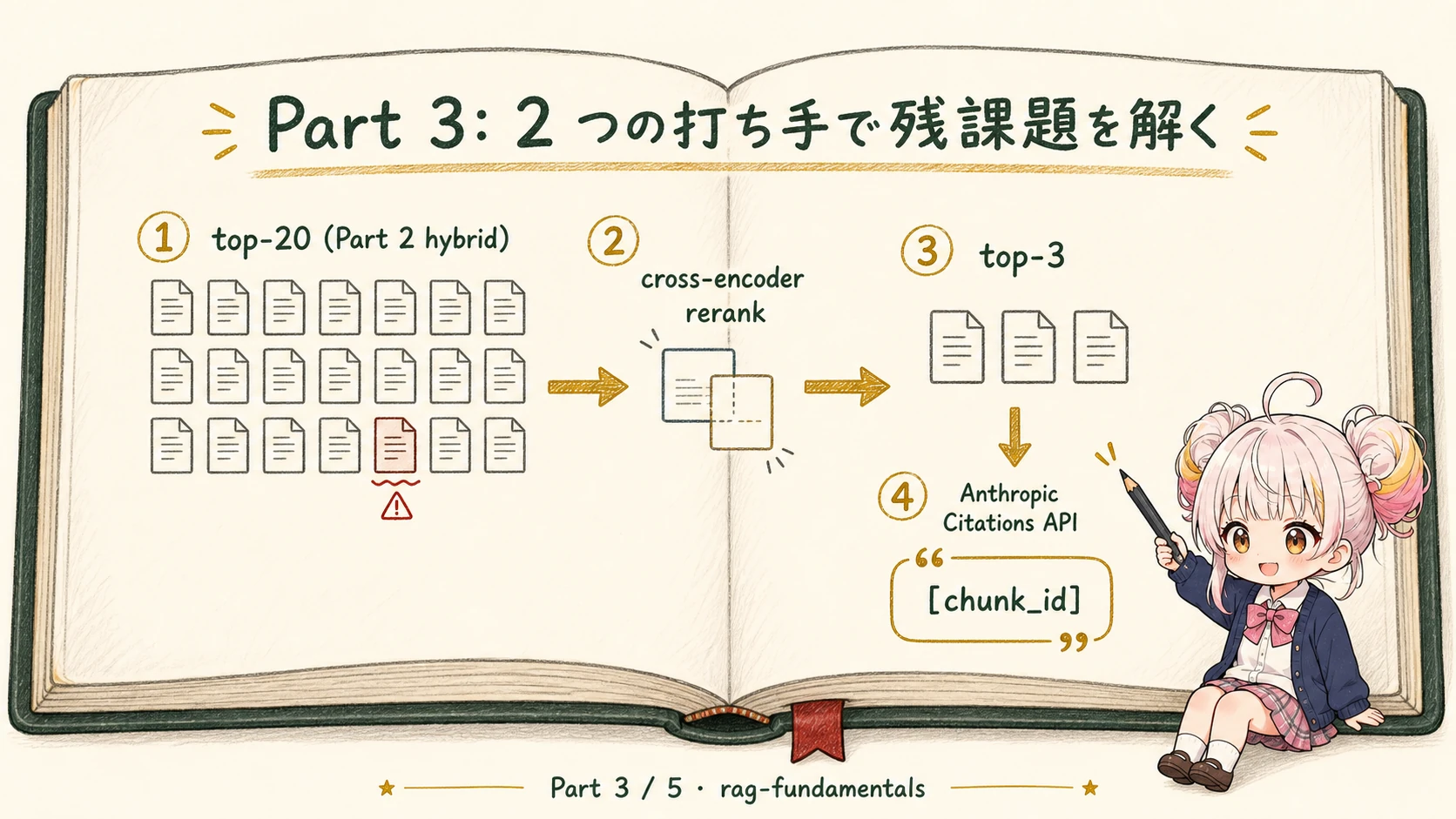
現在地 — フェーズ 2「generation を精密化する」
- 前回まで動いているもの: hybrid+filter で archived 旧版は top-5 から消えた。
- まだ壊れているもの:
status=activeな意味的 trap が hybrid でむしろ 2 位に上がる(A-2)/ 回答の根拠 doc を利用者が検証できない(C-1)。- 今回直す failure mode: 意味的 trap を cross-encoder reranker で top-3 から落とす / citation で doc_id 付き grounding を出す。
- 今回は直さないもの: 「citation は正しいが claim が間違っている」可能性 → Part 4 の Faithfulness。本番ログ・コスト → Part 5。
- 今回の合格条件: trap が top-3 から外れる / doc_id 付き citation が出る。ただし「本当に良くなったか」は単一クエリでは判定しない(aggregate 検証は Part 4)。
用語に不安があれば、地図記事の「概念階段」(embedding=bi-encoder / cross-encoder / reranker の 5 行整理)を先に読むと、この先がぐっと楽になります。
ただし最初に正直なことを書きます。Citations API は 「引用文が source 内に必ず存在する」 ことを構造的に保証するだけで、「主張が正しい」 ことまでは保証しません。cross-encoder reranker も off-the-shelf モデルでは domain mismatch で外れることがあります。本記事は 2 つの打ち手が 何を解き、何を解かないか を観察する立場で、客観評価は Part 4 で RAGAs に持ち込みます。
Part 2 までで残った 2 つの構造的課題
Part 2 で打った 3 手 (heading-aware chunking / BM25+dense hybrid / status filter) は retrieval 側の話でした。Generation 側に持ち込んだ瞬間、別の 2 つの問題が顔を出します。
課題 A-2 — 意味的に近い trap は hybrid で「落ちない」どころか上がる
Part 2 で、クエリ「Mirage 開発でコードレビューに必要な approve 数は?」を 3 段で観察しました。正解は mirage-architecture-v3 の「コードレビュー基準」節 (2 人以上の approve)。ところが nagisa-lt-evaluation (社内 LT 大会の「評価基準」) が 意味的に近い trap として食い込みます。
| stage | trap (nagisa-lt-evaluation) の rank |
|---|---|
| Part 1: dense only | 4 |
| Part 2: hybrid+filter | 2 (悪化) |
dense では 4 位だった trap が、hybrid で 2 位に上がって います。BM25 が「評価」「基準」という表層語を強く拾い、RRF が dense と合算するからです。status filter は archived を落とせても、status=active の trap には無力。これは表層構文の影響を強く受ける bi-encoder の構造的弱点1で、retrieval を真面目にしても 同じ層では届かない天井 です。
課題 C-1 — 「動く citation」と「使える citation」は別物
Part 1 で ### mirage-architecture-v3#00 のような chunk_id ラベルを context に入れたのに、生成側の出力に chunk_id が残らないことを観察しました。prompt engineering で「[citation: doc_id] 形式で引用を出力してください」と指示すれば部分的には動きますが、citation 文字列が 架空 になる (corpus 内に存在しない言い回しに置換される) リスクが残ります2。
社内ナレッジボットの利用者にとってこれは致命的です。「認証は Keycloak です」という回答が現行 mirage-architecture-v3 から来たのか、旧版 mirage-architecture-v2-archive から来たのか — 一見同じ単語でも、根拠ドキュメントによって信頼性は桁違いに変わります。
Cross-encoder reranker で top-20 から top-3 を絞る
最初の打ち手は cross-encoder reranker です。Part 2 hybrid+filter 出力の top-20 を入力に、別モデルで再採点して top-3 に絞ります。このモデルはローカルで動くので、Ollama の 0 円経路でもそのまま再現できます。
なぜ bi-encoder では届かないか — 相互作用の有無
Part 1-2 で使った qwen3-embedding:0.6b は bi-encoder 1 です。query と doc を 独立に ベクトル化して cosine 類似度を取る方式で、「query と doc を組み合わせた時の特徴」は見えません。query 単体の文脈と、doc 単体の文脈が、それぞれ高次元空間でどう配置されるか、だけしか分かりません。
cross-encoder はここが本質的に違います。query と doc を 1 度に同じ transformer に流す ので、相互注意 (cross-attention) で「コードレビューのクエリに対し、LT 大会の評価基準は『評価』が表層一致するが内容は無関係」を判定できます3。
代償は計算量です。bi-encoder は corpus を 1 度埋め込めば検索は近似最近傍探索で O(1) per query ですが、cross-encoder は クエリごとに全候補との pair を forward pass するので O(k) per query になります。だから bi-encoder で候補を絞ってから cross-encoder で rerank が production パターンの定石になりました3。
日本語には多言語 cross-encoder を — bge-reranker-v2-m3
reranker のモデル選択で最優先すべきは 対象言語への適合 です。本記事は BAAI/bge-reranker-v2-m3 を採用します。100 以上の言語で学習された多言語 cross-encoder で、日本語の query-passage ペアを正しく採点できます4。
実は最初、英語ベンチで定番の cross-encoder/ms-marco-MiniLM-L-6-v2 (22.7M, 軽量, Apache 2.0) を試しました。英語 web search では優秀なモデルです。ところが 日本語 corpus では top-20 → top-3 の絞り込みがほぼ的外れになり、関連 chunk を落として Part 4 の aggregate スコアをむしろ下げました (Context Recall が hybrid の 0.87 から 0.66 に regression)。しかもこれは、Part 3 の単一クエリの eyeball test では まったく気づけませんでした — 後述の通り、観察したクエリでは「trap が下がった」ように見えたのです。失敗が判明したのは Part 4 で 30 件を測ったときです。
教訓は明確です。reranker は対象言語で学習されたモデルを使います。英語ベンチの NDCG が高くても、日本語で同じ性能が出るとは限りません。off-the-shelf を盲信せず、自分のデータで測る — まさに本シリーズが Part 4 で示すことの実例になりました。bge-reranker-v2-m3 は 568M とやや重い (ms-marco の約 25 倍) ですが、ローカル CPU/MPS でも top-20 規模なら実用範囲で、Ollama の 0 円経路にそのまま乗ります (RAG_RERANKER_MODEL で差し替え可)。この「英語 reranker が日本語で aggregate を壊した」顛末は §「それでも残るもの」で再訪します。
trap の rank は reranker のモデルで逆転する
実測 (observe-q3) で、nagisa-lt-evaluation の rank が各段でどう動くかを観察しました:
off-the-shelf reranker の罠 — 同じ trap でもモデルで評価が逆転する
「コードレビューの approve 数」クエリでの lt-evaluation (LT 大会評価基準) trap の rank。rank が高いほど trap を下位へ追いやれている (top-5 圏外が理想)
dense で 4 位だった trap は、hybrid+filter で 2 位に 悪化 します (BM25 が「評価」「基準」の表層を拾う)。ここで cross-encoder を 2 段目に挟むのですが、どのモデルを選ぶかで結果が逆転 します。
- ms-marco (英語): trap を 9 位 (top-5 圏外) まで突き落とします。「コードレビュー」と「LT 大会の評価基準」を区別できたように見え、単一クエリの eyeball では大勝利です。
- bge-m3 (多言語、本記事の採用): trap は 3 位までしか下がりません。地味です。
直感的には ms-marco の圧勝に見えます。ところが — これが本シリーズで最も大事な瞬間なのですが — Part 4 で 30 件を測ると評価が逆転 します。ms-marco は単一 trap を派手に落とす一方、日本語の chunk 全体をほぼランダムに並べ替えて関連 chunk を取りこぼし、aggregate の Context Recall を hybrid の 0.87 から 0.66 に下げて しまうのです。bge は per-query では地味でも、aggregate の Context Precision を押し上げます (Part 4 で詳説)。
1 つのクエリの見栄えで reranker を選んではいけません。これは Part 4「測定」のクライマックスへの最良の伏線です。bge での rerank 後 top-3 は mirage-architecture-v3#コードレビュー基準 を先頭に据え、正解文書を確実に上位へ集めます。
Anthropic Citations API で引用を構造化する
2 つ目の打ち手は Anthropic Citations API 5 です。prompt engineering で [citation: doc_id] を要求するアプローチとは別の層で動きます。ここは Anthropic 固有機能なので、ローカル Ollama 経路では --mock で構造だけ確認し、実際の引用付き生成は Anthropic キーを使います。
3 種の document source — RAG では custom content がほぼ正解
Citations API には 3 種類の document source type があり、それぞれ chunking と citation の粒度が違います5。
| Type | Chunking | Citation format | RAG 適性 |
|---|---|---|---|
text (plain text) | 自動 sentence chunking | char_location (0-indexed char range) | RAG chunk より細かい粒度 |
application/pdf | 自動 sentence chunking | page_location (1-indexed page) | PDF 原本のまま |
content (custom content) | 追加 chunking なし | content_block_location (0-indexed block) | RAG chunks に最適 |
公式 docs から直接引用します:
If you want to customize any additional chunking, you can put RAG chunks into custom content document(s). 5
本記事は custom content を選びます。理由は単純で、Part 1-2 で確立した chunk_id ベースの観察可能性を Generation 側まで維持したい から。1 chunk = 1 block で渡せば、start_block_index がそのまま chunk_id に対応します。
documents block の組み立てと cited_text の戻り
top-3 rerank 結果を anthropic SDK の messages content に変換します。最小例:
import anthropic
client = anthropic.Anthropic()
response = client.messages.create( model="claude-opus-4-7", max_tokens=1024, messages=[ { "role": "user", "content": [ { "type": "document", "source": { "type": "content", "content": [ {"type": "text", "text": chunk.body} for chunk in top3_chunks ], }, "title": top3_chunks[0].chunk_id, "context": f"status={top3_chunks[0].doc_status}", "citations": {"enabled": True}, }, {"type": "text", "text": "Mirage 開発でコードレビューに必要な approve 数は?"}, ], } ],)ポイントは 3 つ:
titleに chunk_id (mirage-architecture-v3#コードレビュー基準#00など) を入れると、response のdocument_titleで chunk_id が直接戻るcontextは LLM には渡るが cited_text の対象外 (公式に明記)5。doc 全体のステータス情報や version を入れる場所として最適。Part 2 で抽出したstatus=active/archivedをここに置けば、UI で「現行か旧版か」を出せるcited_textは output tokens に数えません。subsequent turn で送り返しても input tokens に数えません5。prompt engineering で長い citation を要求するより、コスト的にも有利
知っておくべき 2 つの非対称制約
Citations API には設計レベルの非対称制約が 2 つあります。両方とも公式に明記されています5。
- all-or-none: 「citations must be enabled on all or none of the documents within a request」。一部の document だけ citations 有効、は不可
- Structured Outputs と非互換:
output_config.formatを同時指定すると 400 error。citation block と text block の interleaving が strict JSON schema と矛盾するため
逆に tool use / function calling とは併用可能 で、prompt caching とも併用可能 です (cache_control: { type: "ephemeral" } を document block に付与)。本シリーズで言えば、Part 5 で運用視点で扱う prompt caching と組み合わせて、ドキュメント側だけキャッシュする pattern が成立します。
rerank → documents → 引用付き回答 の 1 本のパイプライン
ここまでの 2 つの打ち手は別々に動くわけではありません。retrieve → rerank → documents block → claude.messages.create で 1 本につながります。companion repo の examples/generation/run.py がこの順序を encapsulate します。
prompt_builder.py の責務
src/rag/prompt_builder.py は単純な変換器です。入力は top-3 rerank 後の chunks (Part 2 hybrid+filter の出力 → cross-encoder の出力)、出力は anthropic SDK の messages content 配列。やることは:
- chunk metadata から
title(chunk_id) とcontext(doc status) を抽出 - chunk body をそのまま
content[].textに詰める (custom content なので追加 chunking しない) - system prompt として「Cite specific chunks from the provided documents when stating facts.」を付与
引用付き回答の戻り例 (Anthropic 経路)
クエリ「Mirage 開発でコードレビューに必要な approve 数は?」を Anthropic 経路で叩いた response の構造 (代表例):
response.content = [ {"type": "text", "text": "Mirage のコードレビューでは、PR をマージするのに "}, { "type": "text", "text": "2 人以上の approve が必須です (うち 1 人は他事業部の reviewer が望ましい)", "citations": [ { "type": "content_block_location", "cited_text": "2 人以上の approve 必須 (うち 1 人は同事業部、もう 1 人は他事業部 reviewer が望ましい)", "document_index": 0, "document_title": "mirage-architecture-v3#コードレビュー基準#00", "start_block_index": 0, "end_block_index": 1, } ], }, {"type": "text", "text": "。1 PR あたり 400 LOC までが目安です。"},]document_title に chunk_id がそのまま戻り、cited_text で source 内の実テキストがコピペレベルで取れます。これは prompt engineering では構造的に保証できない property です — citation 文字列が corpus 内に必ず存在する ことを API 側が parse 時に担保しているからです5。LT 大会の評価基準 (trap) は rerank で top-3 から外れているので、そもそも document block に入らず、引用される余地もありません。
「approve は 2 人」の根拠が 現行 mirage-architecture-v3 のコードレビュー基準節 から来たことを、UI で document_title を見出しとして表示するだけで読者に開示できます。
citation の実装は 3 択 — 自分の案件で何を選ぶか
Citations API は強力ですが Anthropic 固有です。自分の案件が別ベンダだったり、ローカル経路だったりするなら、何を保証したいか で選びます。「魔法」ではなく「選択肢」として整理しておきます。
| 実装 | 保証するもの | 保証しないもの | ベンダ依存 |
|---|---|---|---|
prompt で doc_id を出させる | 低コスト・どこでも動く | 架空 citation を防げない | 低 |
| Anthropic Citations API | cited_text が source 内に存在する | claim が正しいとは限らない | 高 |
| 自前 attribution post-check | ベンダ非依存(出力後に照合) | 実装が重い | 低 |
ローカル Ollama 経路では Citations API は構造的に再現できないため、companion repo は prompt 風 citation で代替 します。「引用が付いた=安心」ではなく、どの実装も claim の正しさは別途 Part 4 の Faithfulness で測る 必要がある、というのが要点です。
prompt 風 citation の最小形 — 架空 citation を post-check で弾く
3 択のうち「prompt で出させる」と「自前 post-check」は、組み合わせると 20 行で動きます。Anthropic 以外のベンダやローカル経路で今日から使える形を置いておきます。
import re
CITE_INSTRUCTION = ( "事実を述べる文には、根拠となる chunk を [cite: chunk_id] 形式で文末に付けてください。" "chunk_id は context の ### 見出しに書かれたものをそのまま使ってください。" "context に根拠が無い場合は『資料からは判断できません』とだけ答えてください。")
_CITE_RE = re.compile(r"\[cite:\s*([^\]\s]+)\s*\]")
def find_fake_citations(answer: str, allowed_ids: set[str]) -> list[str]: """出力中の citation を実在 chunk_id と照合し、架空のものを列挙する""" return [c for c in _CITE_RE.findall(answer) if c not in allowed_ids]運用ルールは 1 つだけです。find_fake_citations が空でなければ、その回答はそのまま出しません (破棄して「判断できません」に落とすか、再生成します)。LLM は mirage-architecture-v4#認証#00 のような、もっともらしい架空 ID を平気で作るので、照合無しの prompt citation は「引用風の飾り」にしかなりません。この照合が、表の 3 行目「自前 attribution post-check」の最小実装でもあります。cited 文字列とソース本文の突き合わせまでやれば Citations API の保証に近づきますが、まずはこの ID 照合だけでも架空 citation の大半を落とせます。
それでも残るもの — Part 4 で測定する 3 つの距離
ここまでの 2 つの打ち手で、Part 2 で観察した天井は 構造的に縮みました。けれど距離はゼロではありません。3 つの「残るもの」を Part 4 への伏線として置きます。
「正しい citation」と「正しい claim」の差
Citations API が保証するのは citation 文字列が source 内に存在する ことだけです5。「claim が citation で実際に support される」かは依然として LLM の判断に委ねられます。
Stanford の 2025 研究は、purpose-built な legal RAG であっても 17-34% のクエリで hallucinate すると報告しました6。citation の文字列は valid でも、claim がそれを正しく要約していなければ、結局は誤った回答に valid citation が紐付くだけです。Part 4 では RAGAs の Faithfulness (claim が context に裏付けされているか) で、ここを定量化します。
reranker が言語・ドメインで外れる時
本記事は最初に英語 ms-marco を試し、日本語 corpus で aggregate を悪化させた ので多言語 bge-m3 に切り替えました (§「日本語には多言語 cross-encoder を」)。これは「reranker は対象言語・ドメインで学習されたモデルを使う」という原則の、自分の足で踏んだ生きた実例です。NDCG の高い英語ベンチ番長が、日本語ではほぼランダムソートになり得ます。
bge-m3 でも万能ではありません。法務 / 医療 / 専門 jargon が密な領域では off-the-shelf の精度が落ちます7。その場合は domain-specific な query-document pair に正解 label を付けて fine-tuning するか、LLM-as-reranker のような動的な代替を検討します。本シリーズの corpus 規模では fine-tuning は不要ですが、production で使うときの判断軸として頭に置いておいてください。
context 爆発は top-3 で同時に緩和される副作用
Part 1 で挙げたグループ C-2「context 爆発」は、本 Part の打ち手で 副作用的に同時緩和 されます。top-20 から top-3 に絞れば:
- LLM context への入力 token は 85% 削減 (20 → 3)
- 「Lost in the Middle」(Liu et al., TACL 2023)8 の U-shape 性能低下を回避できる確率が上がる
- follow-up の Hsieh らの calibration 手法9は U-shape を補正できますが、短く絞った context のほうが構造的にトラブルが少ない
ただし top-3 が 常に最適 ではありません。「2023 と 2025 の経費上限の差は?」のような 多文書統合が必要なクエリ では top-k を増やす判断が要ります。これも Part 4 の Context Recall で評価する伏線として置いておきます。
companion repo と次回 Part 4
本 Part の実装は companion repo の part-03 tag で再現できます。Part 1-2 と同じパターン:
ollama pull qwen3:8b && ollama pull qwen3-embedding:0.6bgit clone https://github.com/zawazawa5809/rag-fundamentals-companion.gitcd rag-fundamentals-companiongit checkout part-03uv sync --frozenecho "RAG_PROVIDER=ollama" >> .envuv run python -m examples.generation.run --observe-q3 # trap の rank 推移を実測uv run python -m examples.generation.run --mock # Citations の構造を確認 (キー不要)実装ファイルは src/rag/reranker.py (cross-encoder wrapper、ローカル動作) / src/rag/prompt_builder.py (custom content documents の組み立て) / examples/generation/run.py (Part 2 hybrid+filter → rerank → Citations のエンドツーエンド) の 3 つです。reranker までは Ollama 経路で 0 円再現でき、Citations の引用付き生成だけ Anthropic キーが要ります (RAG_PROVIDER=anthropic_openai)。
ここまでで Part 1 のグループ A (trap) と C (引用喪失・context 爆発) がそれぞれ「部分解決」されました。次回 Part 4 では:
- 30 クエリ × 厳密 golden set
- RAGAs の 4 指標 (Faithfulness / Answer Relevance / Context Precision / Context Recall)
- Part 1-3 の改善が 客観的なスコア改善 として再確認されるか
をクライマックスとして扱います。本 Part の Citations / reranker が「感覚的にはよくなった」ことを、Part 4 で 数字に翻訳 します。
この Part で手元に残る成果物
- reranker モデル選択基準: 自分の corpus の言語・ドメインに合う cross-encoder を選ぶ基準(日本語なら多言語モデル、専門 jargon なら fine-tuning 検討)
- citation 実装選択: 上の 3 択(prompt / Citations API / 自前 post-check)から自分の案件に合うものを選んだ
- trap rank 推移ログ: 自分の意味的 trap が dense → hybrid → rerank でどう動いたかの記録
次の Part に進む条件
- per-query で trap が top-3 から外れたのを確認した
- そして 「単一クエリの見栄えで reranker を選んではいけない」「aggregate で測る必要がある」を理解した(Part 4 の核心。ここで腹落ちしていないと「英語 reranker の罠」を自分でも踏む)
シリーズ全体: 使える RAG の作り方 — 測って・直して・運用する
次回 Part 4: 「評価 (クライマックス) — RAGAs 4 指標で Part 1-3 の改善を客観評価する」
参考文献
Footnotes
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks — Reimers & Gurevych, EMNLP 2019. bi-encoder の表層 bias (Part 1, 2 でも引用) ↩ ↩2
Attribution Techniques for Mitigating Hallucinated Information in RAG Systems: A Survey — 2026 survey。citation 系手法の分類と limitation ↩
Retrieve & Re-Rank — sentence-transformers — 公式 2 段 pipeline 解説。cross-encoder の cross-attention と計算量トレードオフ ↩ ↩2
BAAI/bge-reranker-v2-m3 - Hugging Face — 多言語 cross-encoder reranker (約 568M, XLM-RoBERTa-large ベース, 100+ 言語対応)。比較対象の英語専用 ms-marco-MiniLM-L-6-v2 は 22.7M / Apache 2.0 と軽量だが日本語では精度が出ない ↩
Citations - Claude API Docs — 公式仕様。citations.enabled / 3 source types / cited_text の input/output token 非計上 / Structured Outputs 非互換 / prompt caching 互換性を一次参照 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools — Stanford 2025。purpose-built RAG でも 17-34% hallucinate ↩
Cross-Encoder Reranking in Practice: What Cosine Similarity Misses — 2026-04。off-the-shelf cross-encoder の domain mismatch 実証 ↩
Lost in the Middle: How Language Models Use Long Contexts — Liu et al., TACL 2023。U-shape 性能、関連情報が中央で大幅劣化 ↩
Found in the Middle: Calibrating Positional Attention Bias Improves Long Context Utilization — Hsieh et al., ACL Findings 2024。calibration で長 context retrieval を +15pp 改善 ↩